
Last time, we talked a little bit about entropy and classical information theory. If you haven’t already, check that article here. It gives a good introduction to this one, introduction so good that I have serious trouble writing another one here. Hopefully this short introduction will be over soon.
At the end of the previous post I mentioned that classically, probabilities are quite simple and that it gets much more complicated in a quantum case. Why exactly? And what is the “quantum case”?
Quantum mechanics is the language of modern physics. It is a base on which more complicated theories can be built, for example regarding behaviour of particles and fields, describing new phases of matter, interactions of lasers and atoms, or collective motion of solid materials. But all these theories rely on quantum mechanics. Some people, like Scott Aaronson [1], claim that quantum mechanics is at its core a theory about probability and information. It is just a more… complex one. Literally. As he puts it in his book:
“But if quantum mechanics isn’t physics in the usual sense – if it’s not about matter, or energy, or waves, or particles – then what is it about? From my perspective, it’s about information and probabilities and observables, and how they relate to each other.”
Let’s say you have a box, and in that box you have, say, 3 oranges, 5 apples and a pear. You reach inside and you grab one fruit. It is easy to see, because we are used to classic probability theory, that a chance of grabbing an orange is 



Scientists started developing quantum mechanics because they encountered a range of peculiar phenomena which their classical theories failed to account for. Now we know that the fundamental reason behind this was that the classical probability theory fails to describe things happening at very small scales. Classically, if a probability of one event is 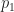
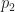

In the quantum world, probabilities are changed to something called probability amplitudes. We can add probability amplitudes of two similar events to get an amplitude of a joint event (either the first or the second thing happens). Amplitudes are different from probabilities – first, they can be negative! What is more, it can actually be shown that for this theory to be consistent, amplitudes will sometimes have to be complex numbers. Second, it’s their squared moduli (if you are not familiar with complex numbers, think about squared modulus as a “square” of a complex number which ends up being a real number) what adds to
What exactly we are supposed to be adding? Should it be the squared moduli or the amplitudes themselves?
Any quantum system can be described as being in some state. That state is a mixture of several basis states, as described above. We are allowed to play with that state. Change it, make it evolve. We say we apply quantum operations, make the state interact with the enviroment, apply magnetic fields, shine light onto it. The state then changes. In particular, these operations might involve two different states at least partially evolving into the same state, with different amplitudes. Or the same state evoling into some other state in two different ways! In that case, to find out what is the total amplitude of that state in the mixture, we add the amplitudes coming from different processes, but ending up in the same state. Then the resulting amplitude is the amplitude of that state.
After these operations, we usually want to measure the state. By measuring, we ask a quantum system the question: which state are you in? But this question is not an open one! It is a close one. We have to pick all the possible answers we can get. The number of these answers is limited to the dimension of the system. For a single qubit, the dimension is two, so we can only get two different answers, the system can only tell is that it is in one of the two states that we pick. But if the state is somewhere in between, we are forcing it to change by performing the measurement, we are forcing it to become a different state, one of the ones we picked. The probability of that happening is the square of the amplitude associated with that state. If we then prepare another, identical state, and perform the measurement again, we might get a different answer, even if we do everything exactly in the same way. This is because quantum mechanics is instrinsically probabilistic (well, according to most interpretations at least). If we want to then calculate the probability of getting either one or the other states, we enter the classical zone and we first square the amplitudes of each state and then add these squares for the joint probability.
For example, let’s imagine a quantum particle that travels from a point A to one of the points B or C. These are somehow the only two points where it can end up. On its way, it can either travel through point X or point Y, but that is not known – we never learn which path was taken by the particle, but we do know where it ended up in. We thus add amplitudes of particle travelling through X to B and through Y to B too get an amplitude of ending up at point B. And then we do the same for point C, add amplitudes of travelling through X to C and through Y to C, and then we square the whole thing to get the probability. Now, if we add the two squares, this will add up to one. This is because in macroscopic scale probabilities are classical, and because B and C are different states, easily distinguishable, the classical rules apply.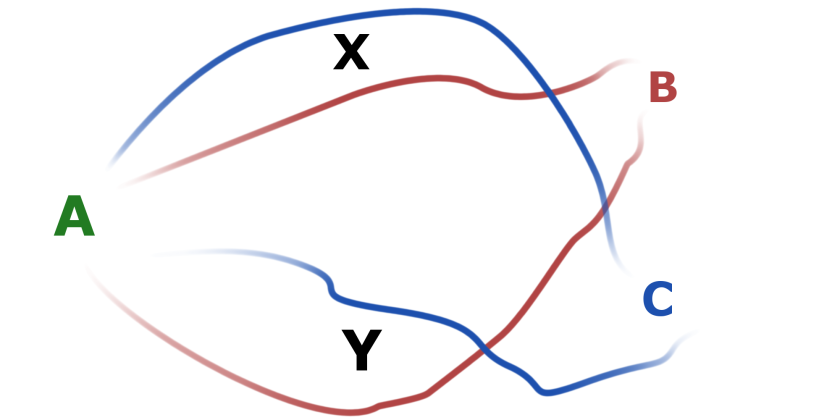
Because these amplitudes are in general complex numbers, it is possible that the amplitude of getting through X to B and an amplitude of getting through Y to B are opposite numbers and they add up to 0! In which case the existence of two different paths leads to a complete cancellation of any possibility of a particle ending up at B. This is the paradox scientists were struggling with: if you only have one path, the particle can end up at B, if you have only another one, the particle can still end up at B, but when both paths are available, it becomes impossible suddenly.
This is resolved by using an alternative probability theory. In fact, this assumption about probabilities, that they can involve negative numbers is the only one you need to make to recreate quantum mechanics. The fact that probabilities work differently than we previously thought is what underlies most of the modern physical theories.
But okay, we wanted to talk about information, right?
To talk about quantum information, we need a fundamental portion of it. In classical world, it was called a bit, a number, either 0 or 1. Something that either is or isn’t. It was realised by a physical system, which could remain in two separate states, for example magnetized or demagnetized, black or white, up or down. It is important to remember information is and always was physical, needed a physical realization. In the quantum world, we have qubits. Qubits
also are physical objects, that can occupy two independent quantum states, which are traditionally denoted as 



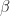

A quantum system may remain in such state as long as it is not disrupted in any way. The problem is, we don’t usually know what the state is exactly. And trying to find out – a measurement, is already a disruption of some sort, because it has to involve some physical process that interacts with the state, and such states are really fragile. When we see things, photons need to reflect off them and reach our eyes, when we hear them, air particles vibrate on the way from the source to our ears, when we touch things, electrical signals travel through our body to our brains. The interaction has to be there for anything to be observed, and really what is important is that it happens, not that its products reach our bodies. In other words, the existence of a human or other conscious being is not needed for a measurement to be conducted. Unfortunately, it is a common misconception among laymen and that needs to be stressed.
One of the reasons quantum information is so different from classical is a mysterious quantity that has no equivalent in a classical world, entanglement. Entanglement is a property of a system consisting of many particles, and it is a peculiar way the states of particles this system consists of are correlated. An example of an entangled system is a pair of photons of opposite polarisations. Before measurement, we know that the polarisations are opposite, but we don’t know exactly what are their directions. After we measure only one of these polarisations – we can measure it in whatever way we want, along any axis we choose, and that way will affect the result, the second one becomes defined and exactly opposite to the first one! It turns out that entanglement has many peculiar properties, some of which are not yet completely understood.
Classically, systems that are correlated, can be correlated to different levels, some pairs of variables are correlated very strongly, and some only a little bit. For example, there is a very strong correlation between your age in years and your age in minutes – it is basically the same quantity, but in different units. But there also is correlation between the age and height across children – older kids are going to in general be taller, but people have different heights, because that is partially determined by genetics, so younger children might be taller than older ones if their parents are especially tall. So there are different levels or degrees of correlation even classically. Similarly, we can find that there are different degrees of entanglement. Some pairs of systems can be strongly entangled, and some only to some level. A fascinating result is that it can be extracted from physical systems which are not completely entangled to form a fewer number of systems which are, so it can be treated as a resource. What’s more, entanglement of a single particle is limited – if the particle is completely entangled with another particle, it cannot be entangled with anything else. [3] It is called monogamy of entanglement and we can see that it is completely different from the classical correlation, because classically, you can have as many systems strongly correlated with each other as you manage to create. This is because entanglement is not just statistical correlation. It is much stronger, because in quantum mechanics you can measure the state of the system in many different ways, and entanglement forces correlation in each of these measurements, not just one.
That is why quantum systems can be correlated much more than classical systems because of entanglement. This is how physicists have confirmed that the world cannot be purely classical, that is, levels of correlation which are classically proven to be impossible are actually possible in practical experiments involving highly entangled particles!
For example, think about a following game. There are two players, Alice and Bob, who collaborate to win. Each of them has a standard deck of cards and every turn, draws one card from the deck and doesn’t show it to the other player. Then, basing on the card that they’ve drawn, each of them decides either to push a button or not. They have to make their decisions simultaneously, so that they are not affected by the other’s decision. Now, if they both pushed their buttons or they both haven’t, they win provided at least one of the cards they’ve drawn was red. But if one of them pushed their button and the other have not, they win only if both their cards were black.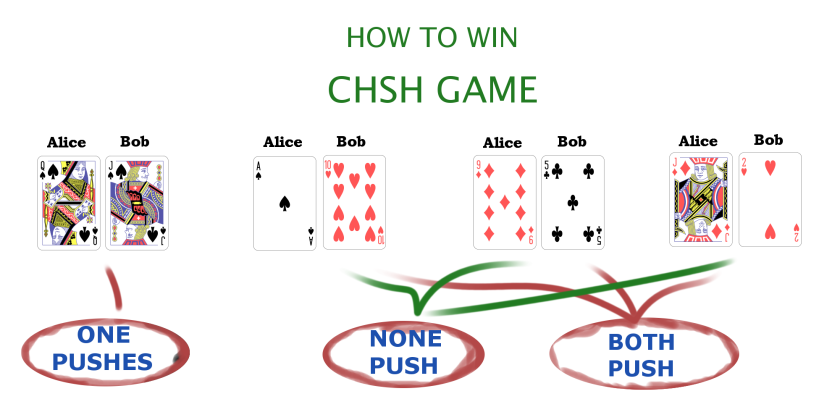
It is quite easily seen that they can win in 
However, if the choice of a card from the deck is determined not by sheer luck, but by a clever quantum measurement of a half of entangled quantum state Alice and Bob share between each other, the probability can go up to about 85%! That beats the classical result which can be proved to be correct. Both Alice and Bob only measure their own qubit, which has exactly 50% chance to be in one of two states, what can be associated with a card being either red or black, so the probabilities work out. Also, they can be very far away from each other, so that for any information from the other party was to influence their decision, it would have to travel much faster than the speed of light in a vacuum. However, despite all this, the quantum nature of entanglement still bumps up probabilities to 85%! That has been confirmed experimentally, and it is a realization of one of the Bell inequalities. These inequalities are rigorous statements, which reality would have to satisfy if it was purely classical or at least local, what means, there would be some local hidden influences, which cannot be seen directly, but which change the way it behaves. Experimentally, however, it was in most cases confirmed that it doesn’t satisfy those, and actually it comes close to what non-local quantum theory predicts.
Entanglement is just one of the resources that quantum information theory utilizes, and which make it much richer than classical theory. What the quantum information theory tries to do is to find out about what other types of information are there in the quantum world, because there are certainly more than in the classical world, what other types of information processing are there, and then what can we actually do with those and what exactly are the limits we have to obey while performing those processes, how do this different types of information change, are created and then destroyed.
The researchers managed to find many, many more such types, listing them all here would not be possible, so for now try to think about this and come back in two weeks for more!
In the meantime, you can read more about entanglement and quantum mechanics here:
- An excellent semi-popular book by Scott Aaronson about information and computation “Quantum computing since Democritus” with more details about the approach that I have basically stolen from him.
- Bennett, Charles H.; Bernstein, Herbert J.; Popescu, Sandu; Schumacher, Benjamin (1996). “Concentrating Partial Entanglement by Local Operations”. Phys. Rev. A. 53: 2046–2052 – the first paper about entanglement distillation.
- V. Coffman, J. Kundu and W. K. Wootters, Phys. Rev. A 61, 052306 (2000), a paper that introduced monogamy of entanglement.
- The “Bible of quantum computing” with chapters about quantum mechanics and entanglement “Quantum computation and quantum information” by Michael Nielsen and Isaac Chuang
- Definetely also check out Scott’s blog: https://www.scottaaronson.com/blog/
- Very short description of quantum computing, from one of research group at University of Strathclyde, I am including it because it is short and I took one of the images from this site, I hope they don’t mind because it was really nice.
 particles in that box, and so there is a plethora of exact configurations of their positions and momenta, the parameters that are in principle needed to fully, exactly describe the system. In most of them, the particles would appear to be almost evenly spread across the box. Now, let us think about the unusual configurations, when all the particles are in the right half of the box, and are randomly spread there. There are much fewer such configurations, so that is much less probable. How exactly?
particles in that box, and so there is a plethora of exact configurations of their positions and momenta, the parameters that are in principle needed to fully, exactly describe the system. In most of them, the particles would appear to be almost evenly spread across the box. Now, let us think about the unusual configurations, when all the particles are in the right half of the box, and are randomly spread there. There are much fewer such configurations, so that is much less probable. How exactly?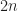 equally probable little spaces the particles can occupy, no matter how big these spaces actually are, then there are
equally probable little spaces the particles can occupy, no matter how big these spaces actually are, then there are  configurations in the case when particles can be spread out across the whole box. But in a half of the box there are only
configurations in the case when particles can be spread out across the whole box. But in a half of the box there are only  spaces, what means only
spaces, what means only  configurations – a square root.
configurations – a square root.
 is entropy,
is entropy,  is a number of possible states – arrangements in this case, in general this also involves momenta, and
is a number of possible states – arrangements in this case, in general this also involves momenta, and  is a Boltzmann constant. This equation shows that the entropy of a half filled container is a half of the entropy of a full container. It however assumes that each microstate has an exact same probability to occur. If the probabilities are different, equal to
is a Boltzmann constant. This equation shows that the entropy of a half filled container is a half of the entropy of a full container. It however assumes that each microstate has an exact same probability to occur. If the probabilities are different, equal to  , the entropy changes to Gibbs’ form, given by
, the entropy changes to Gibbs’ form, given by
 -s by
-s by  , one over the number of microstates, which is a probability of a single microstate if they are all the same. This is because the minus sign in front inverts the argument of the logarithm.
, one over the number of microstates, which is a probability of a single microstate if they are all the same. This is because the minus sign in front inverts the argument of the logarithm. appears with probability
appears with probability  , then entropy of a source is:
, then entropy of a source is:
 letters long, with the most efficient coding we are going to need on average
letters long, with the most efficient coding we are going to need on average  bits to encode it.
bits to encode it. ,
,  . We can calculate the entropy of this source:
. We can calculate the entropy of this source:
 + 25%
+ 25%  . Exactly equal to the entropy value! Basically, the number of bits we aim to use for each letter should be as close as possible to
. Exactly equal to the entropy value! Basically, the number of bits we aim to use for each letter should be as close as possible to  , where
, where  . It can be then shown that if we introduce so-called binary entropy function
. It can be then shown that if we introduce so-called binary entropy function  the rate of compression has to be proportional to
the rate of compression has to be proportional to  . The closer
. The closer  is to 1, the more bits we need in order to transfer the message. This makes sense,
is to 1, the more bits we need in order to transfer the message. This makes sense,  corresponds to
corresponds to  , and that means we can have no idea whatsoever about what the message actually was, as exactly a half of the bits are flipped, so the message looks like a completely random string.
, and that means we can have no idea whatsoever about what the message actually was, as exactly a half of the bits are flipped, so the message looks like a completely random string.
